|
Yuanze Lin I am a DPhil (PhD) student in the Computer Science Department at the University of Oxford, where I work on diffusion and multimodal large language models. I have also worked at Microsoft Research, MSR Asia, Alibaba, and CCVL @ Johns Hopkins University. I appreciate collaborating with distinguished professors and researchers from these institutions. My research builds generative and multimodal foundation models that perceive, reason about, and generate the physical 3D world: • Physically grounded video generation and 3D world models • Spatial, 3D, and embodied reasoning in multimodal LLMs • Unified vision–language models across diverse tasks |
 |
|
|
 |
IllumiCraft: Unified Geometry and Illumination Diffusion for Controllable Video Generation
Yuanze Lin, Yi-Wen Chen, Yi-Hsuan Tsai, Ronald Clark, Ming-Hsuan Yang NeurIPS, 2025 ArXiv / Project Page / Video / Code / BibTeX We present IllumiCraft, a unified framework that unifies geometry and illumination diffusion for controllable video generation. |
 |
Olympus: A Universal Task Router for Computer Vision Tasks
Yuanze Lin, Yunsheng Li, Dongdong Chen, Weijian Xu, Ronald Clark, Philip Torr CVPR, 2025 ★ Highlight ArXiv / Project Page / Video / Poster / Code / BibTeX Turns MLLMs into a universal task router that handles a wide array of computer vision tasks within a single unified framework. |
 |
Text-Driven Image Editing via Learnable Regions
Yuanze Lin, Yi-Wen Chen, Yi-Hsuan Tsai, Lu Jiang, Ming-Hsuan Yang CVPR, 2024 ArXiv / Project Page / Video / Poster / Code / BibTeX A region-based network trained with a CLIP-guided text-driven loss, editing images from freely provided language descriptions. |
 |
SMAUG: Sparse Masked Autoencoder for Efficient Video-Language Pre-training
Yuanze Lin, Chen Wei, Huiyu Wang, Alan Yuille, Cihang Xie ICCV, 2023 ArXiv / Poster / Slides / BibTeX An efficient video-language pre-training framework that stays competitive on retrieval and video QA while cutting pre-training cost by 1.9X or more. |
 |
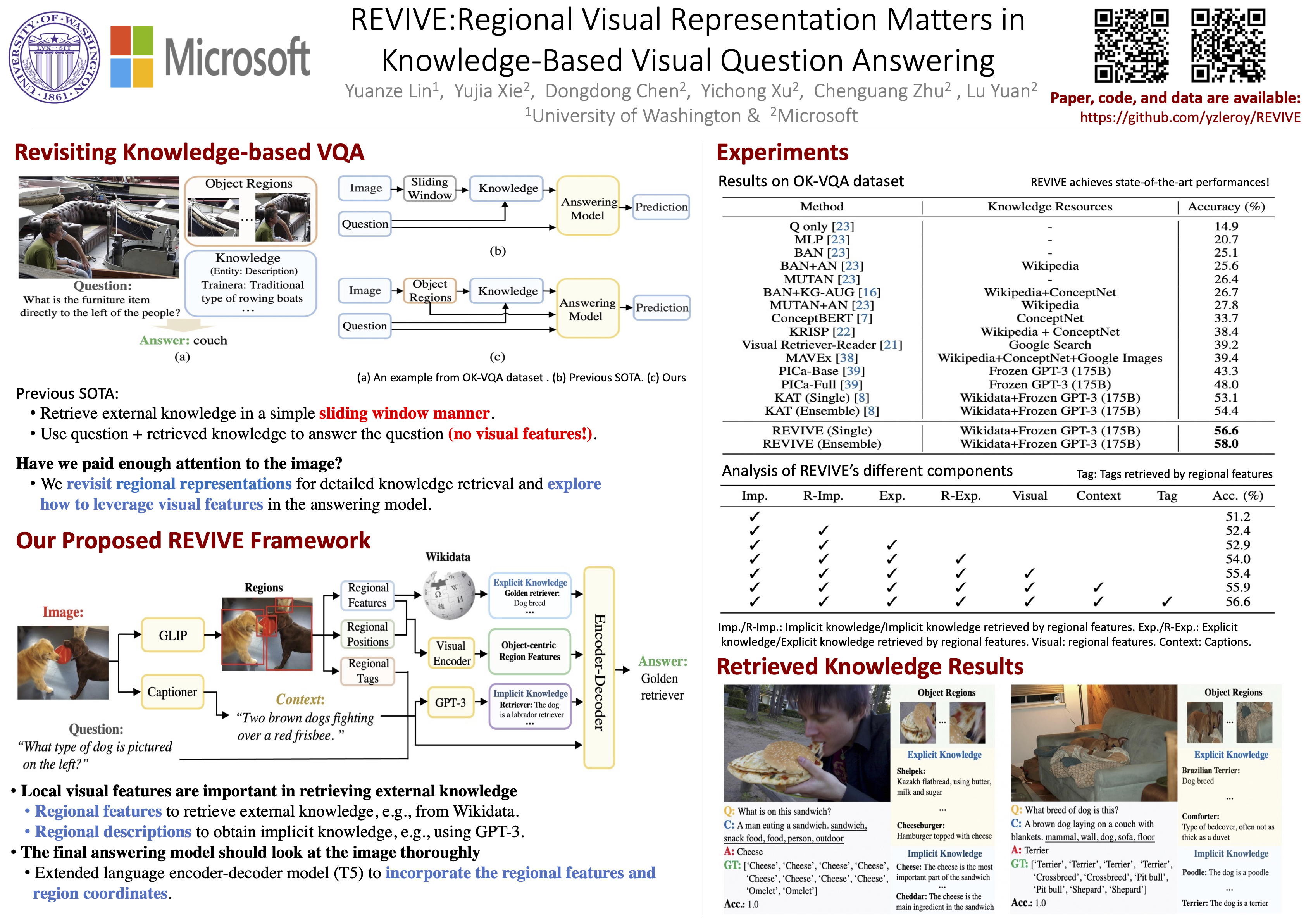
REVIVE: Regional Visual Representation Matters in Knowledge-Based Visual Question Answering
Yuanze Lin, Yujia Xie, Dongdong Chen, Yichong Xu, Chenguang Zhu, Lu Yuan NeurIPS, 2022 ArXiv / Poster / Supplementary Material / OpenReview / Code / BibTeX A knowledge-based VQA method exploiting explicit object-region information in both retrieval and answering, reaching state-of-the-art on OK-VQA. |
 |
Pseudo-Q: Generating Pseudo Language Queries for Visual Grounding
Haojun Jiang*, Yuanze Lin*, Dongchen Han, Shiji Song, Gao Huang CVPR, 2022 ArXiv / Poster / Code / BibTeX Automatically generates pseudo language queries for supervised training, matching or beating weakly-supervised visual grounding across five datasets. |
 |
AdaFocus V2: End-to-End Training of Spatial Dynamic Networks for Video Recognition
Yulin Wang*, Yang Yue*, Yuanze Lin, Haojun Jiang, Zihang Lai, Victor Kulikov, Nikita Orlov, Humphrey Shi, Gao Huang CVPR, 2022 ArXiv / Code / BibTeX Reformulates AdaFocus as a one-stage algorithm via differentiable patch selection and an improved training scheme, validated on six benchmarks. |
 |
Self-supervised video representation learning with meta-contrastive network
Yuanze Lin, Xun Guo, Yan Lu ICCV, 2021 ArXiv / Poster / BibTeX A Meta-Contrastive Network combining contrastive and meta-learning for pre-training, surpassing prior methods on UCF101 and HMDB51. |
 |
EVA-GCN: Head Pose Estimation Based on Graph Convolutional Networks
Miao Xin, Shentong Mo, Yuanze Lin CVPR AMFG Workshop, 2021 🏆 Best Paper Award Paper / Code / BibTeX Builds a landmark-connection graph and uses Graph Convolutional Networks to model nonlinear mappings from graph topology to head-pose angles. |
|
|
|










{kind=link}
{kind=link}
|
Last Update: 07/2026 Template |