With the user-provided textual instructions, DreamPolisher can generate high-quality and view-consistent 3D objects.

With the user-provided textual instructions, DreamPolisher can generate high-quality and view-consistent 3D objects.
We present DreamPolisher, a novel Gaussian Splatting based method with geometric guidance, tailored to learn cross-view consistency and intricate detail from textual descriptions. While recent progress on text-to-3D generation methods have been promising, prevailing methods often fail to ensure view-consistency and textural richness. This problem becomes particularly noticeable for methods that work with text input alone. To address this, we propose a two-stage Gaussian Splatting based approach that enforces geometric consistency among views. Initially, a coarse 3D generation undergoes refinement via geometric optimization. Subsequently, we use a ControlNet-driven refiner coupled with the geometric consistency term to improve both texture fidelity and overall consistency of the generated 3D asset. Empirical evaluations across diverse textual prompts spanning various object categories demonstrate DreamPolisher’s efficacy in generating consistent and realistic 3D objects, aligning closely with the semantics of the textual instructions.


Optimus Prime, with
blue and red
color scheme

An action figure of
Iron Man, Marvel's
Avengers, HD

A DSLR photo of
a brown horse
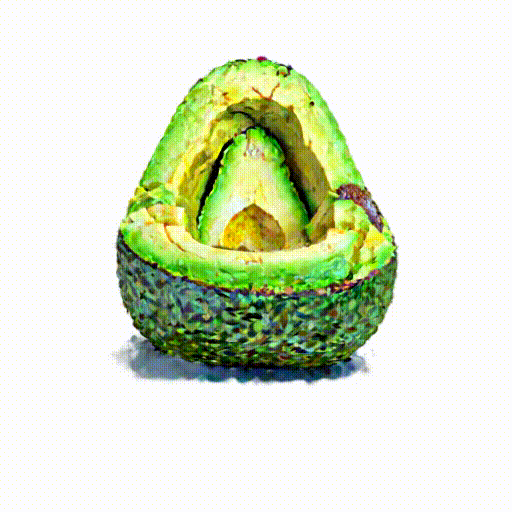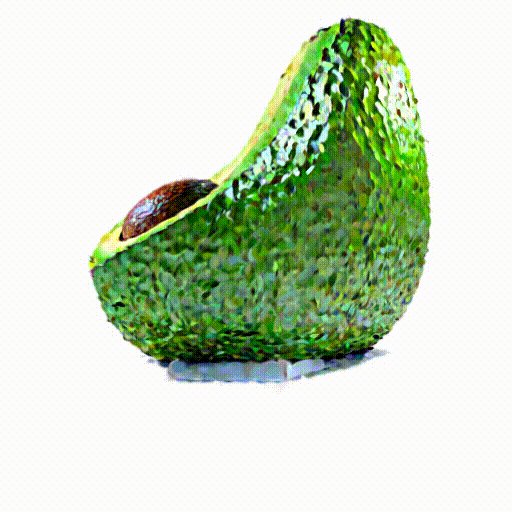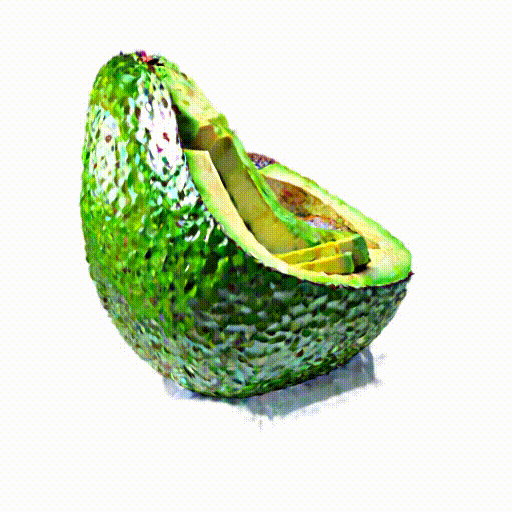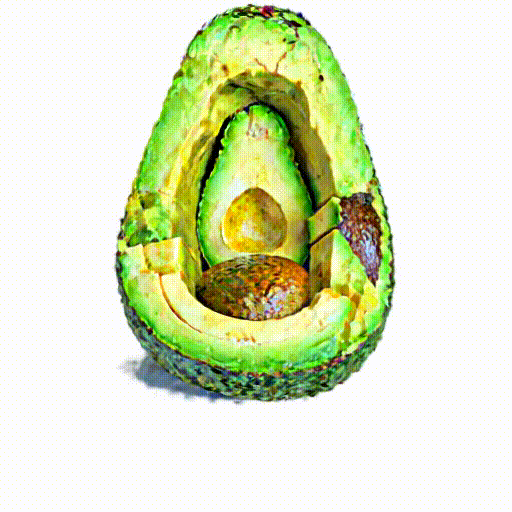
An avocado chair,
a chair imitating
an avocado

A stunning, antique
silver candelabra with
intricate candle holders

A cozy sofa with
soft upholstery and
tufted detailing

A juicy, medium-rare
filet mignon garnished
with fresh herbs

A modern red
motorcycle with
advanced features

An old bronze compass,
brintricately engraved,
pointing northward

A lustrous pearl necklace,
with a delicate clasp
and shimmering surface

The ancient ruins of
Angkor Wat, a UNESCO
World Heritage site

A Mediterranean style
house with terracotta tiles

A cuddly panda
bear, with black
and white fur

A rugged, vintage-inspired
hiking boots with
a weathered leather finish

An antique lamp casts
a warm glow, igniting
a fire
Given the text prompt, DreamPolisher will perform two-stage training, including coarse optimization (stage 1) and appearance refinement (stage 2):
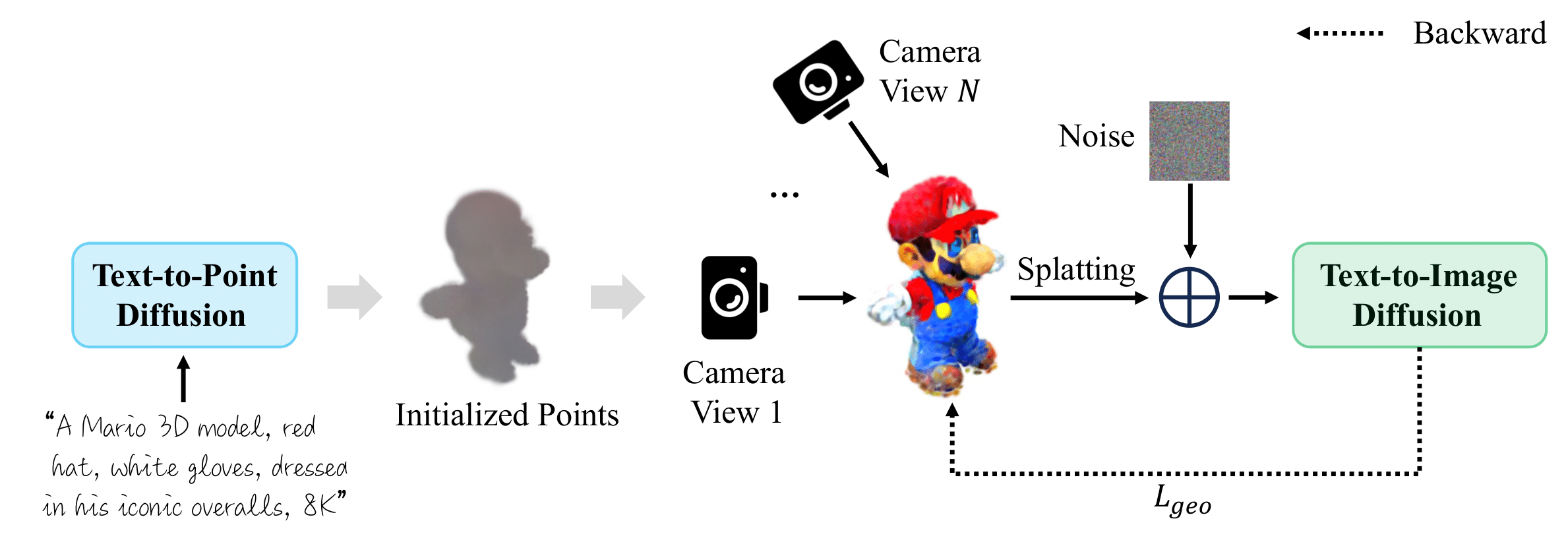
Coarse Optimization (Stage 1). The text prompt is firstly fed into a pretrained text-to-point diffusion model, e.g., Point-E [29] to obtain the corresponding point cloud, which is used to initialize the 3D Gaussians. After that, we use 3D Gaussian Splatting to optimize the object Gaussians guided by the pre-trained text-to-image diffusion model.
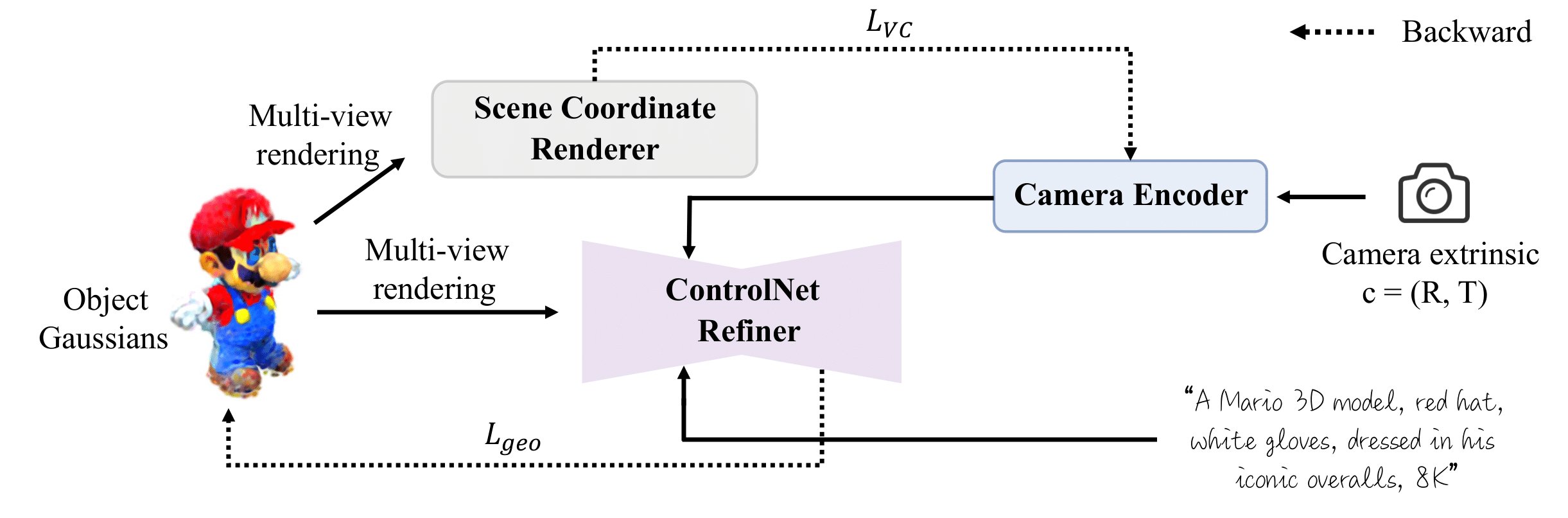
Appearance Refinement (Stage 2). We render multiple views from the 3D object optimized by the coarse stage, and feed them to the Scene Coordinate Renderer. The rendered scene coordinates are then used in the view consistency loss, which aims to ensure that nearby scene points have consistent colors. The geometric embeddings from the camera encoder and the rendered multiple views are then fed into the ControlNet Refiner to generate high-quality and view-consistent 3D assets.

@article{lin2024dreampolisher,
title={DreamPolisher: Towards High-Quality Text-to-3D Generation via Geometric Diffusion},
author={Lin, Yuanze and Clark, Ronald and Torr, Philip},
journal={arXiv preprint arXiv:2403.17237},
year={2024}
}