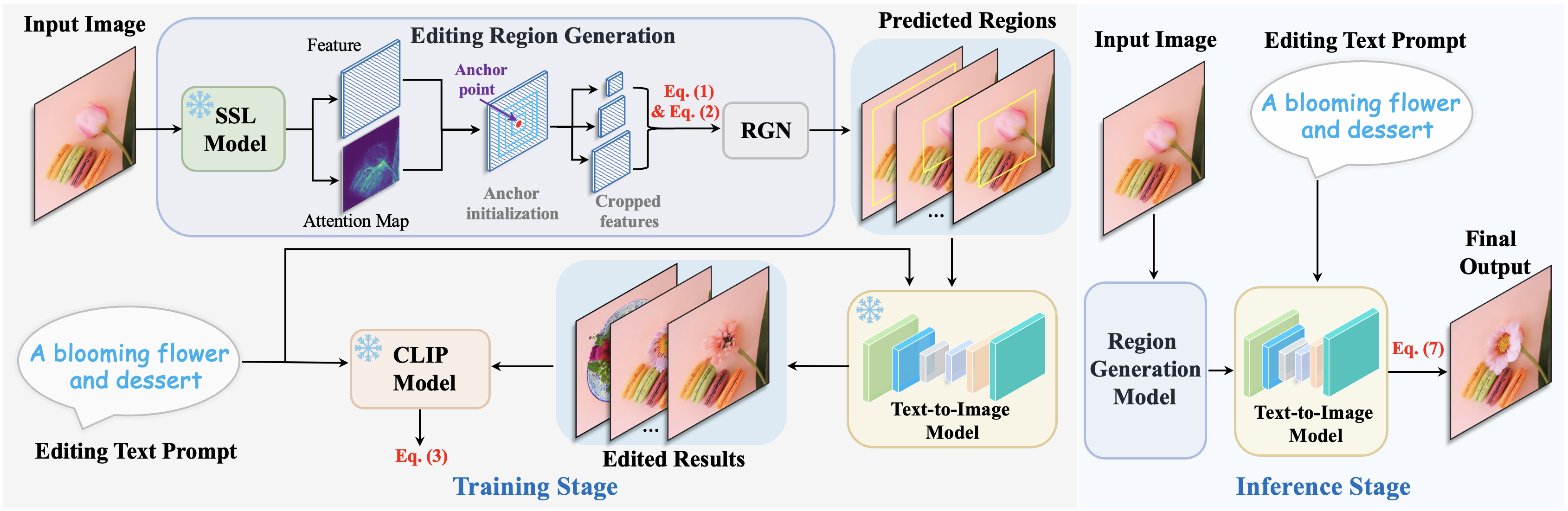
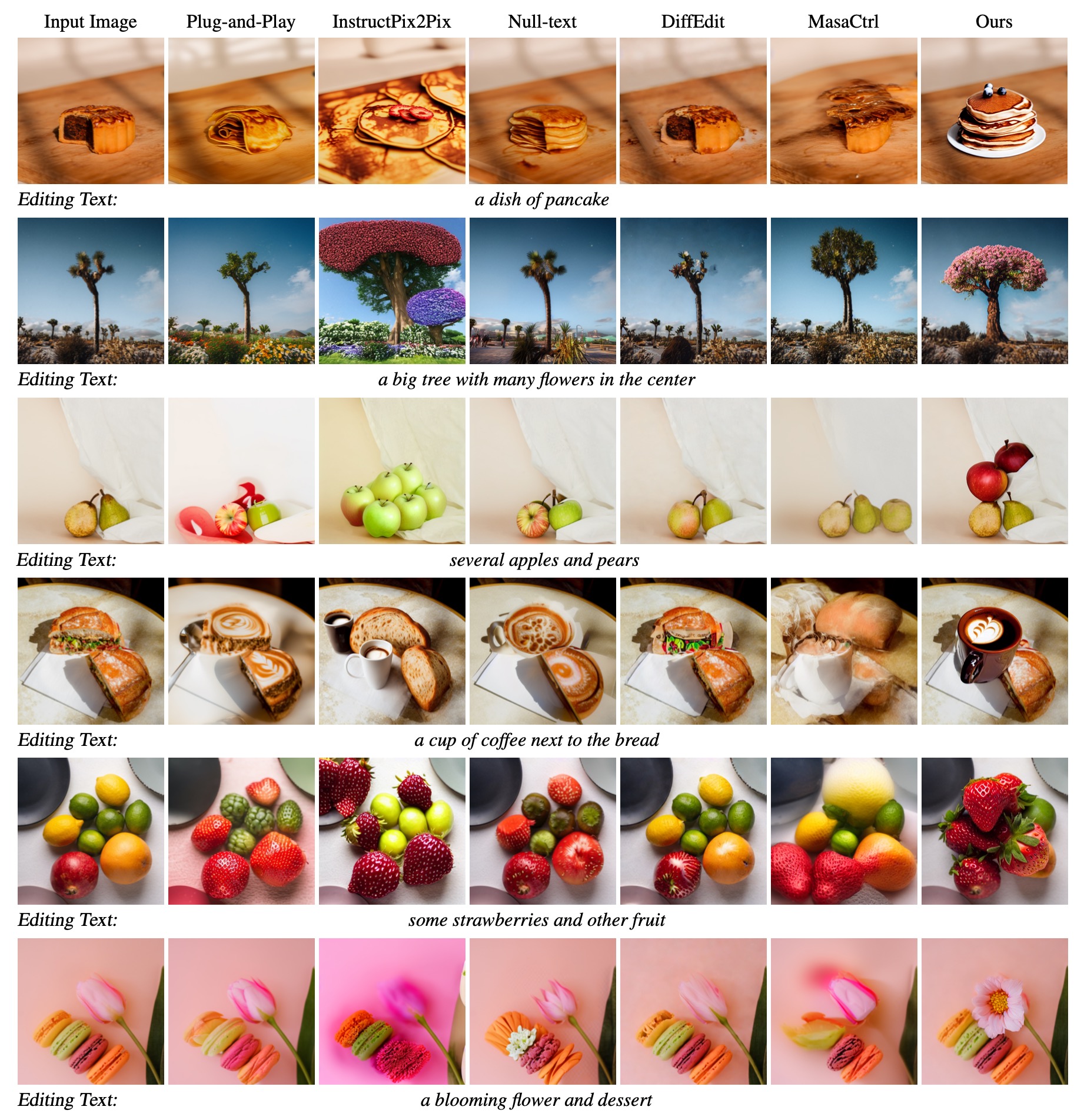
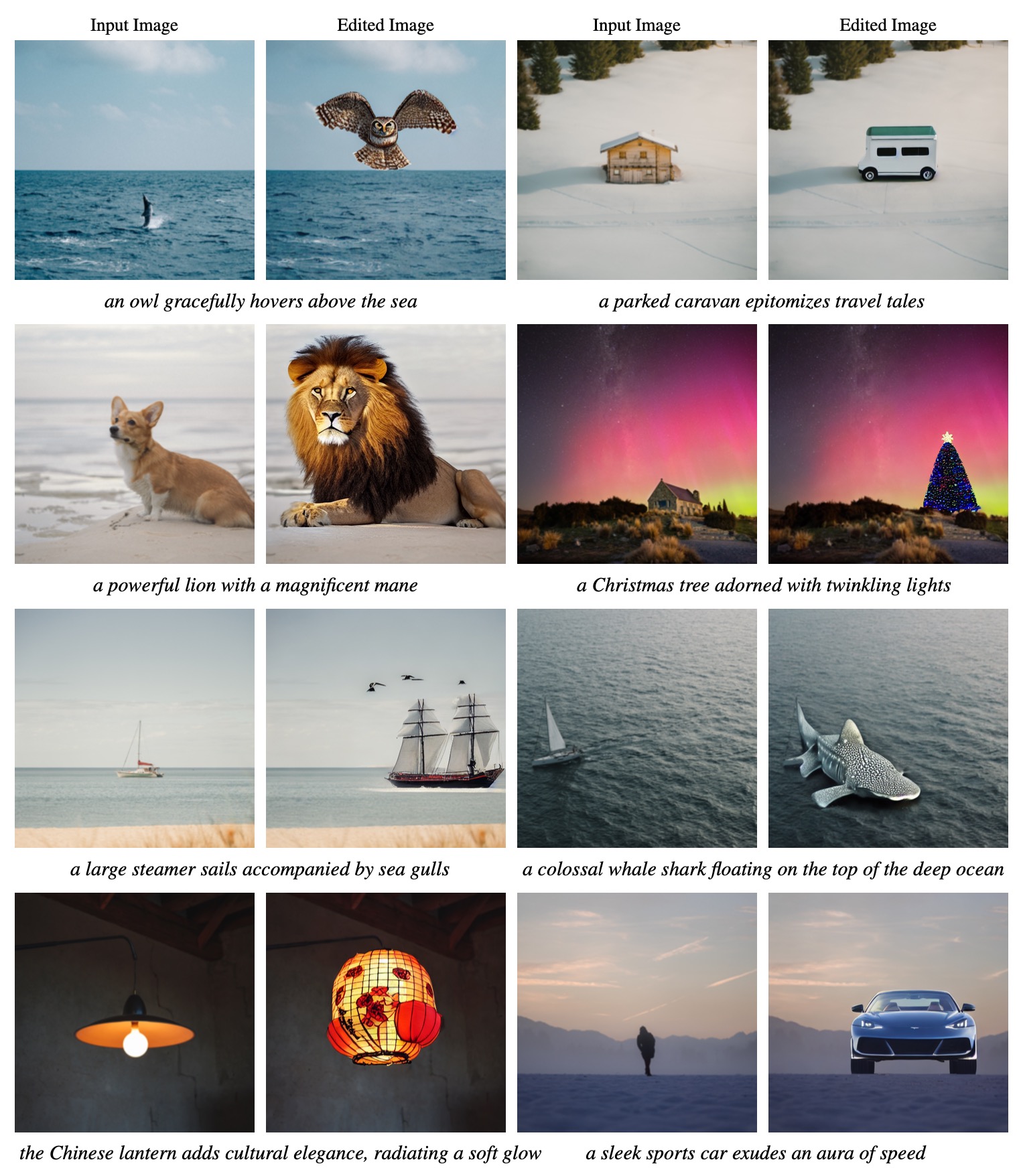
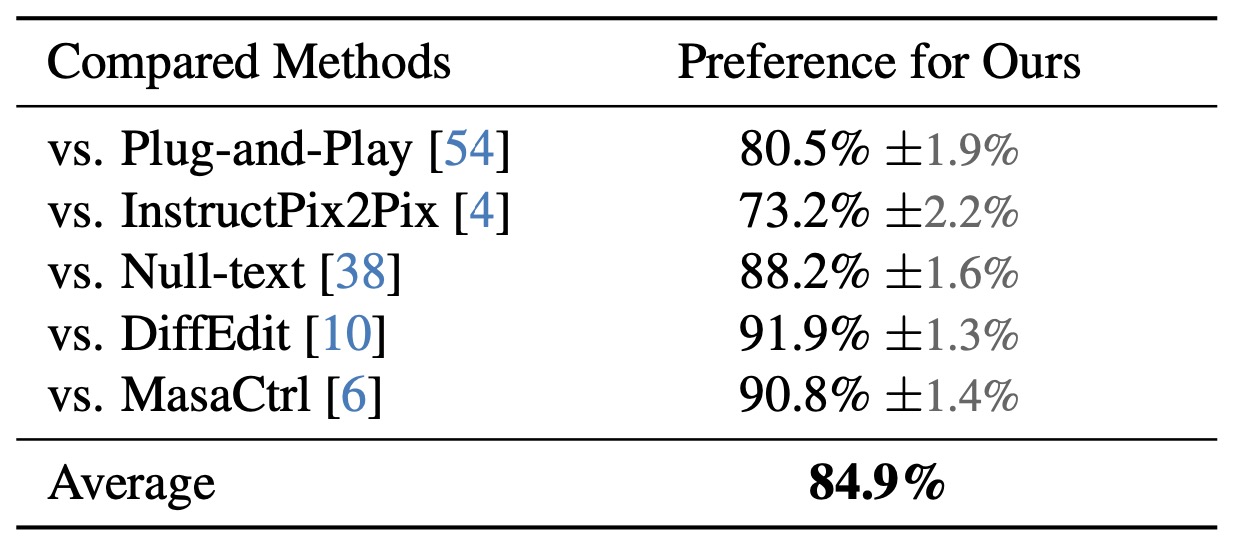
Given an input image and a language description for editing, our method can generate realistic and relevant images without the need for user-specified regions for editing. It performs local image editing while preserving the image context. Our method can also handle multiple-object and long-paragraph scenarios.